http://www.sohu.com/a/119630435_472869
PhxSQL设计与实现 2016-11-22 17:59
PhxSQL是一个开源项目,开源地址:
https://github.com/tencent-wechat/phxsql
点击阅读原文可自动跳转到github地址
PhxSQL是一个兼容MySQL、服务高可用、数据强一致的关系型数据库集群。PhxSQL以单Master多Slave方式部署,在集群内超过一半机器存活的情况下,可自身实现自动Master切换,且保证数据一致性。
相比目前业界流行的MySQL高可用方案,PhxSQL有三个优势:
不少MySQL高可用方案只实现了高可用,不保证数据强一致;PhxSQL完美地同时满足了高可用和强一致;在主备数据一致性上,PhxSQL达到了和zookeeper同样的级别;
PhxSQL的高可用方案不依赖zookeeper这类第三方选主服务,对比其他的高可用方案在部署上更加简单;
完全兼容MySQL,已有的MySQL应用程序完全不需要做任何的修改就能迁移到PhxSQL。
本文以PPT的形式来阐述一下PhxSQL的设计与实现。从MySQL的容灾缺陷开始讲起,接着阐述实现高可用强一致方案的思路,然后具体分析每个实现环节要注意的要点和解决方案,最后展示了PhxSQL在容灾和性能上的成果。
https://www.cnblogs.com/lijingshanxi/p/9976237.html
严格的来说,微信开源的phxsql不是数据库,而是一个数据库的插件;
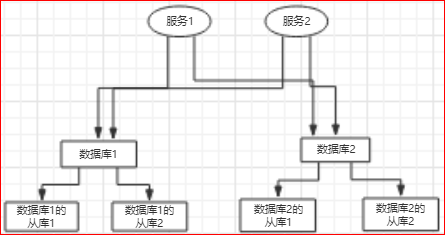
传统的互联网数据库结构一般是这样的:
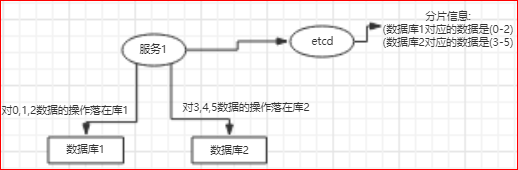
服务访问数据库是通过分片来的:
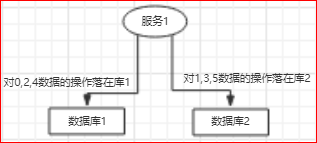
除了这种基于hash的分片,还有一种基于range的分片方式
通常,基于range的分片场景下会引入一个新的服务来保存range分片的元信息,列如etcd:
数据库连接是这样进行的:
第1步, 先监控etcd服务上的range信息变化;
第2步, 读取etcd服务上的range信息;
第3步, 接收到sql请求,解析sql语句,根据分片信息决定连接哪个数据库进行操作;
著名的开源数据库TiDB就是range来做数据库的水平拆分;
基于hash的数据库分片现在已经很少用了,因为扩容时非常麻烦;你可以自行脑补一下,1000台数据库的记录扩展到1500台,在不中断业务的情况下的操作;
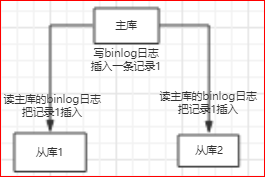
上面的内容有点跑题,我们接下来看看主从复制:
为了防止某个库挂掉之后,记录丢失,有了主从复制
当然,主从复制还可以满足读写分离,减低主库的负担
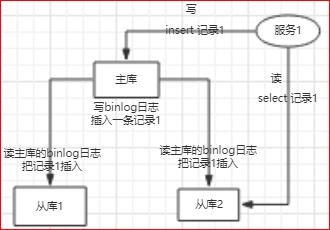
数据库连接的逻辑:
第1步, 解析sql;
第2步, 判断sql是读(insert, update, delete)还是写(select);
第3步, 落到相应的库上;
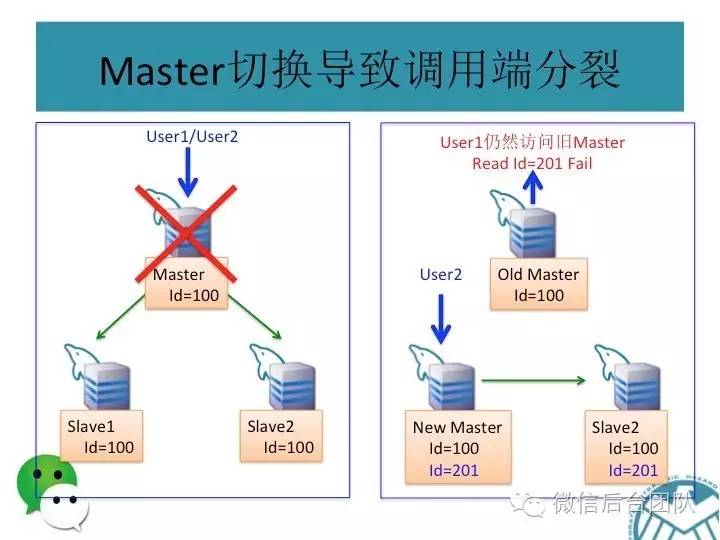
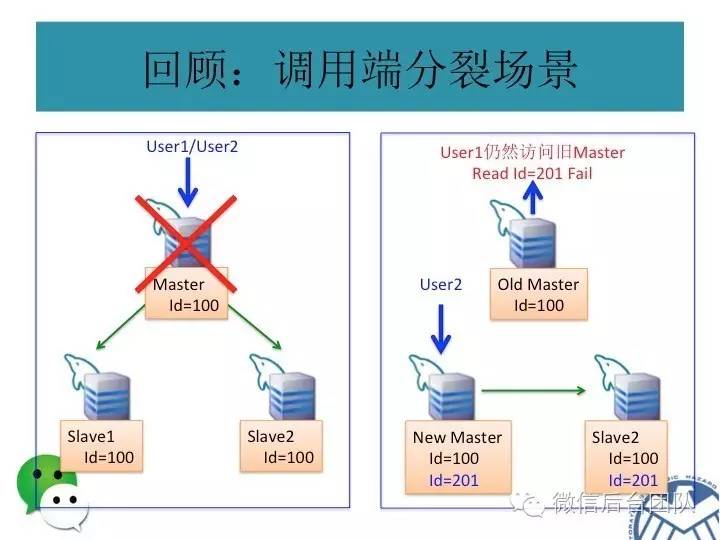
由于从库获取主库的记录有延时,所以读可能会失败,比如你刚发布了个帖子,却不能马上查到;
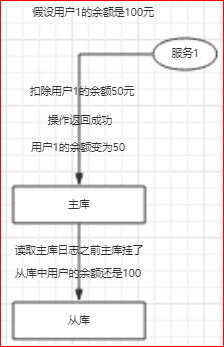
或者还有更坏的情况,你刚发了个帖子,主库挂了,这条记录还没同步到从库;这样帖子就丢了;
如果只是丢了帖子,情况还不算糟,重新发个帖子就是了;如果是在金融场景下,问题可能就麻烦了,比如下面的场景:
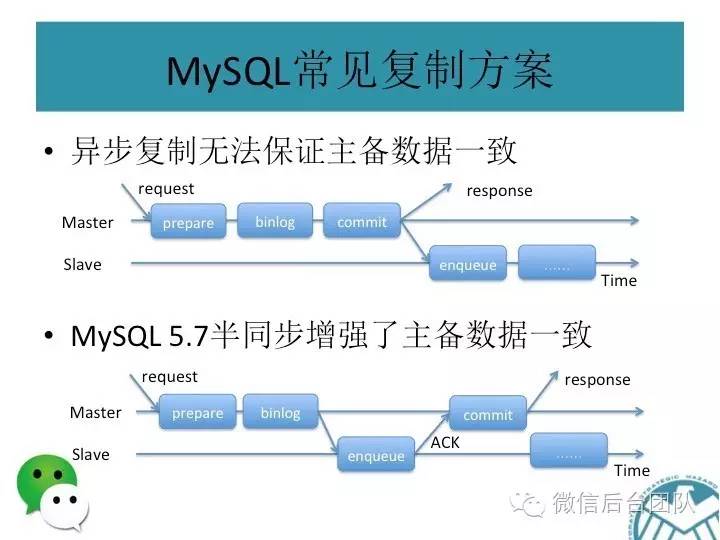
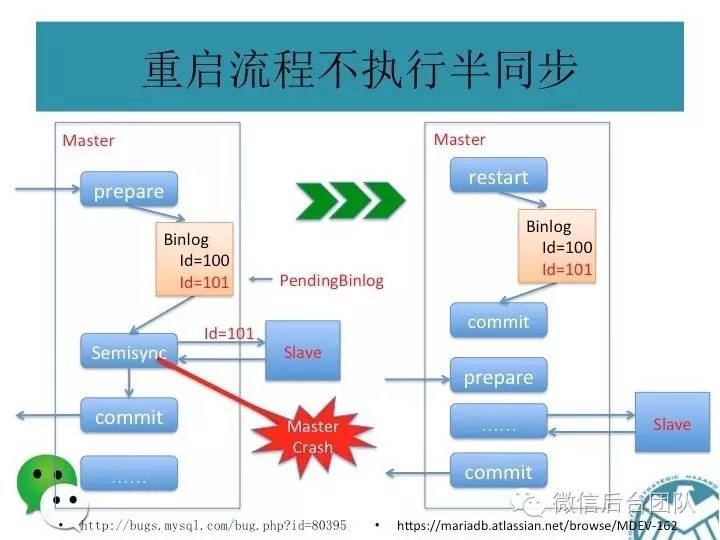
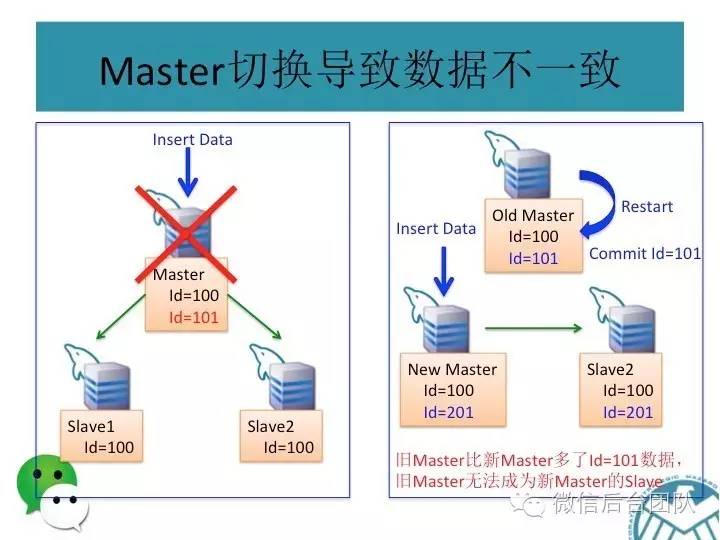
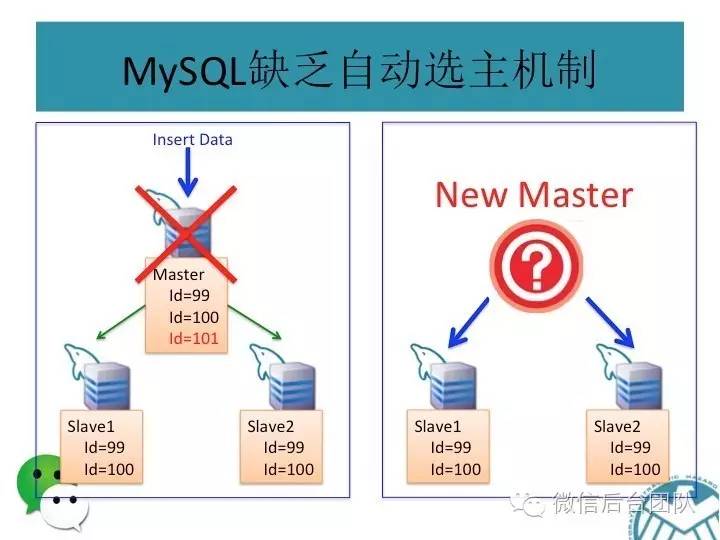
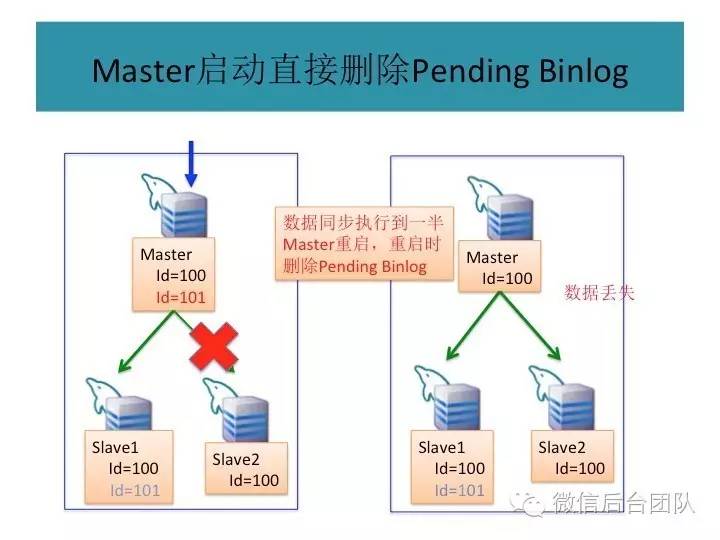
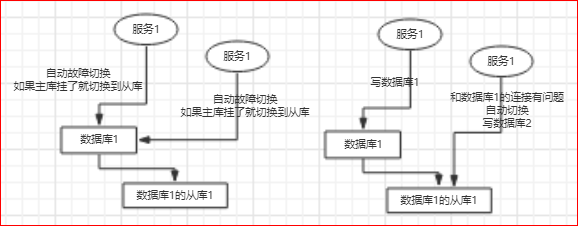
mysql主从复制可能会导致数据不一致,这是问题1;
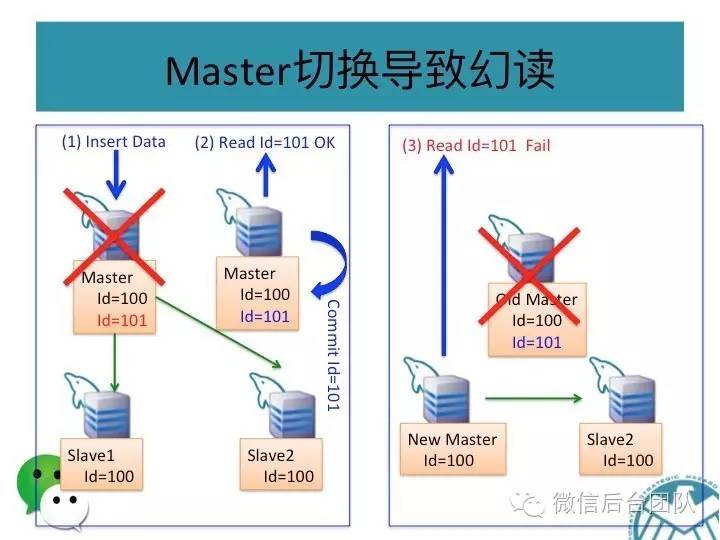
再看下面的场景,如果数据库连接是基于故障自动切换的,则有可能会产生主库和从库同时被写的问题;
这种场景下,主从库的数据也会不一致,这是第二个问题;
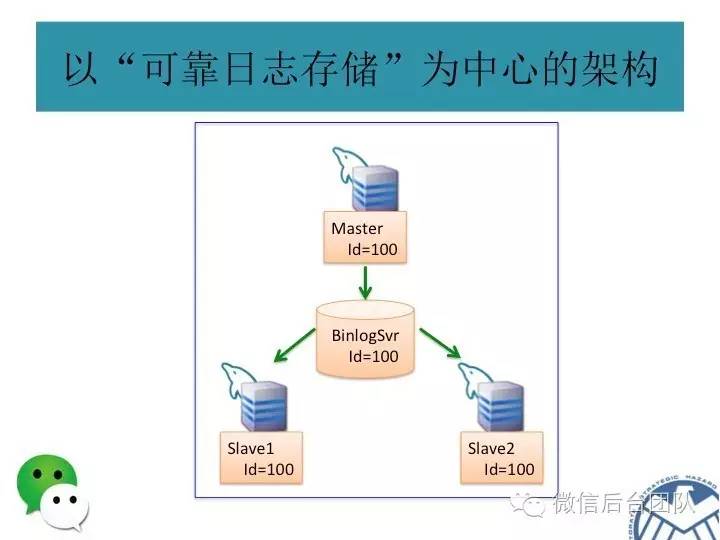
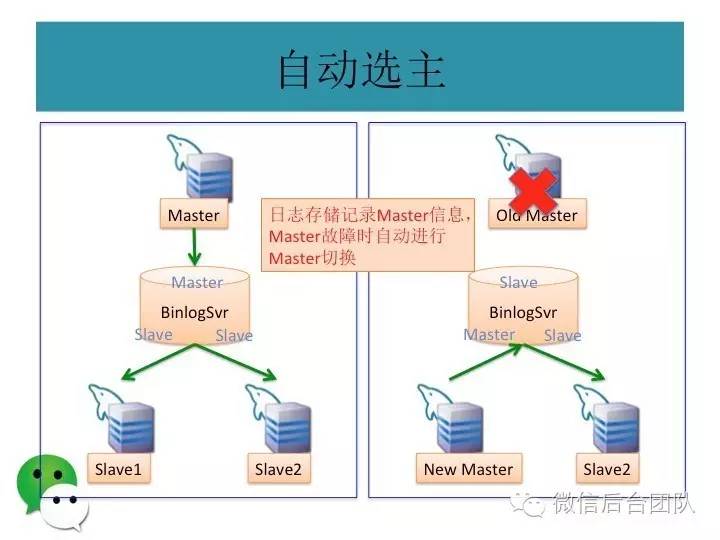
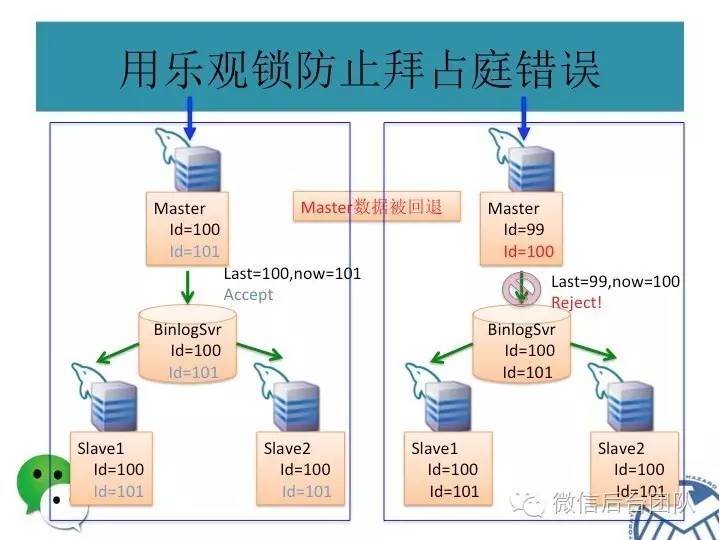
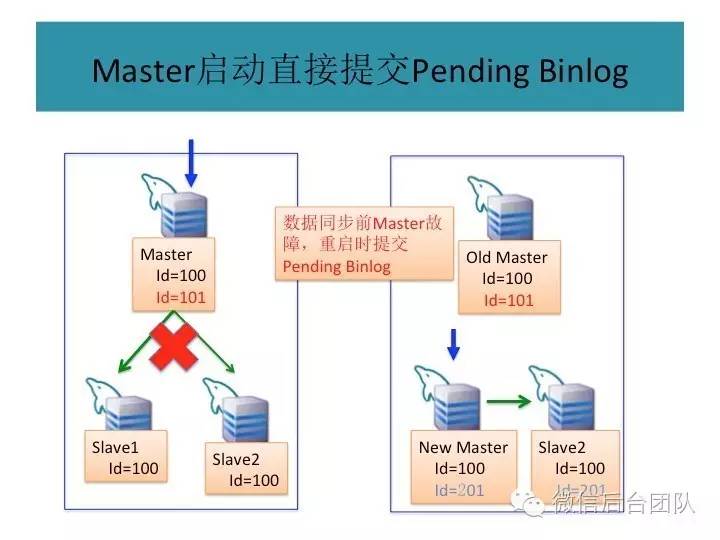
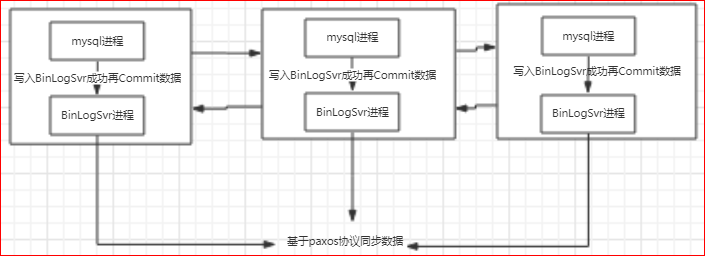
为了解决第一个问题,phxsql引入了第一个插件BinLogSvr:
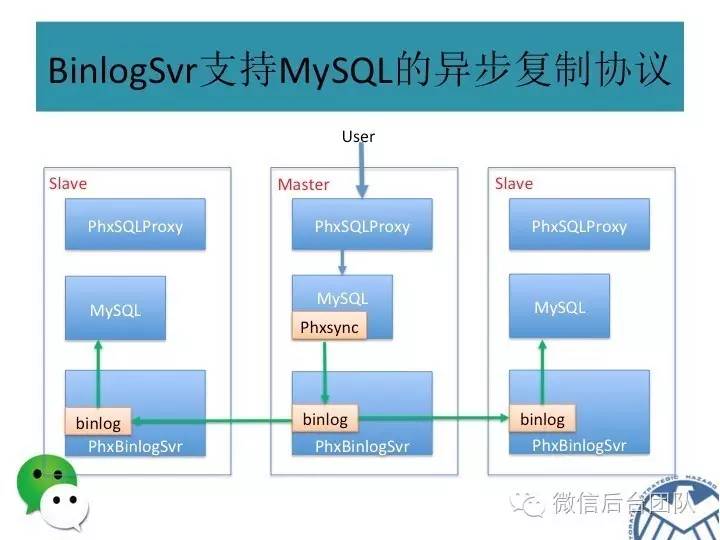
phxsql增加了一个进程BinLogSvr,用来管理mysql日志;
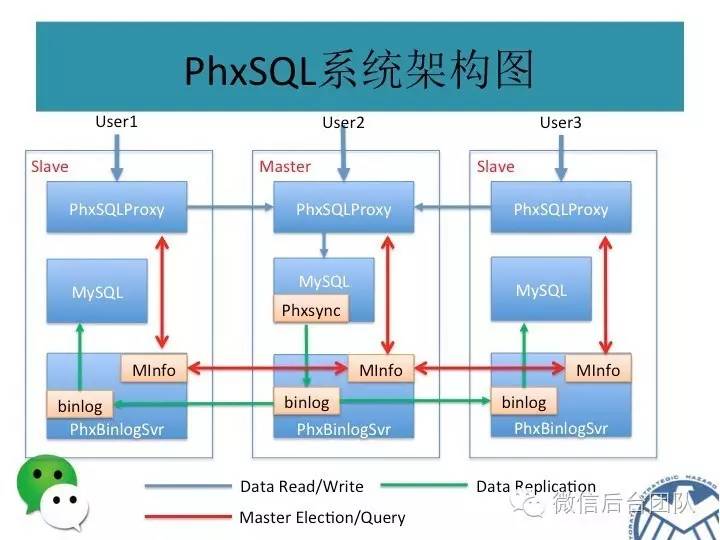
主库的逻辑变成了这样:
第1步, 收到sql请求;
第2步, 准备sql执行;
第3步, 写入BinLogSvr;
BinLogSvr用paxos协议,将这条日志复制到mysql集群中的其他机器上;
BinLogSvr返回成功;
第4步, Commit数据,返回成功;
从库的逻辑变成这样:
取消从主库获取binlog;
改成从本机的BinLogSvr获取binlog;
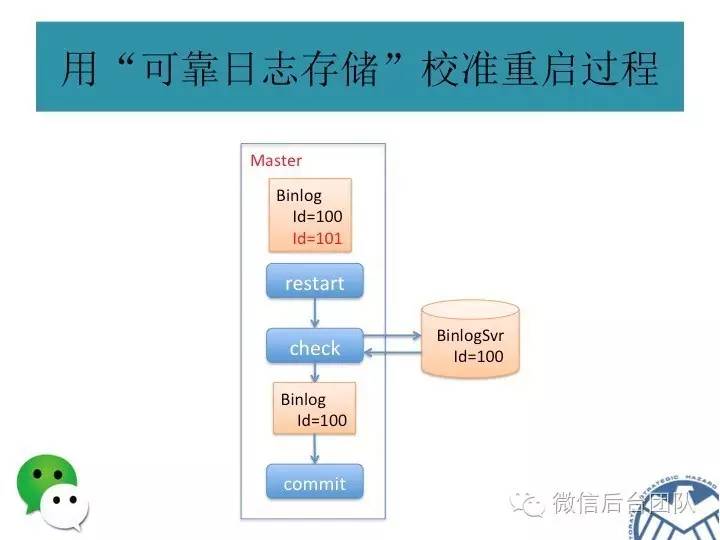
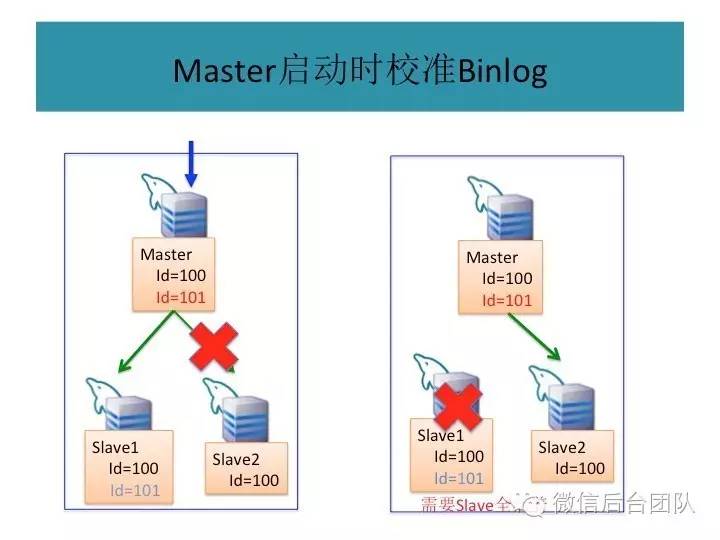
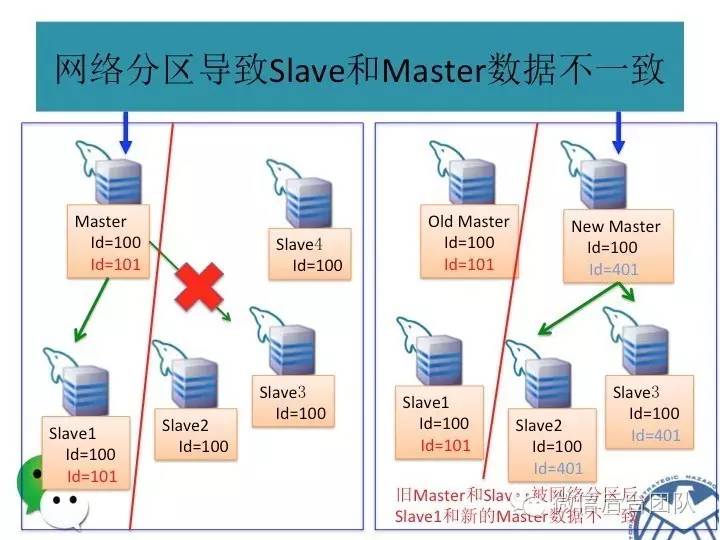
由于BinLogSvr基于paxos协议,binlog到BinLogSvr成功即表明mysql集群中半数以上的机器已经获取到最新的日志,除非半数以上的机器挂掉,才有可能产生数据不一致;
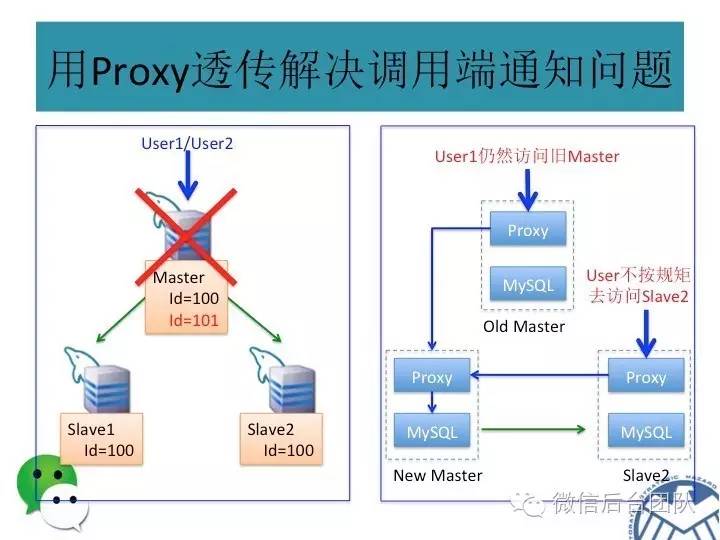
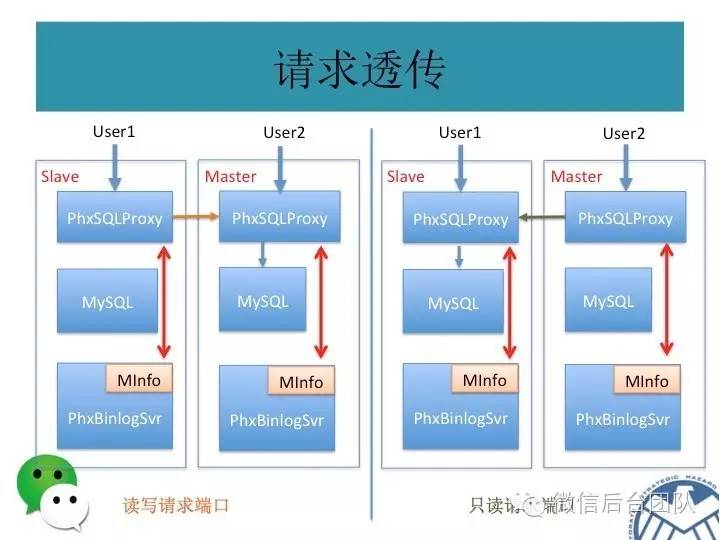
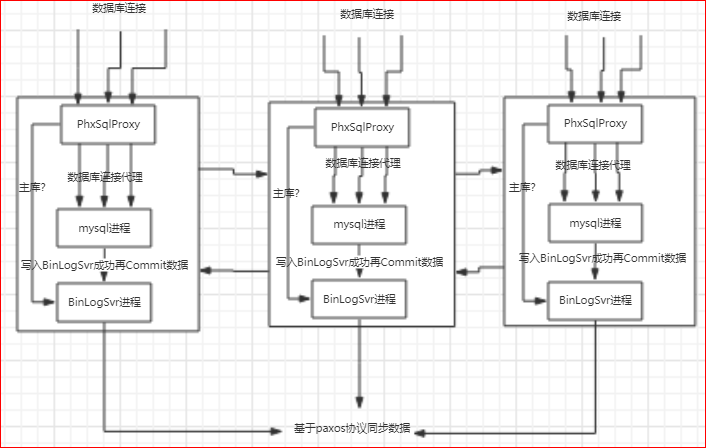
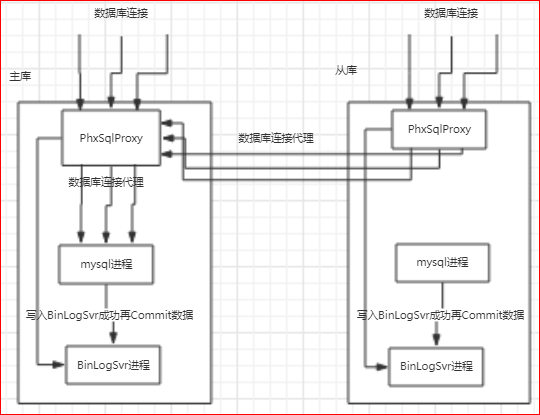
为了解决上述的第二个问题,phxsql引入了另一个插件PhxSqlProxy:
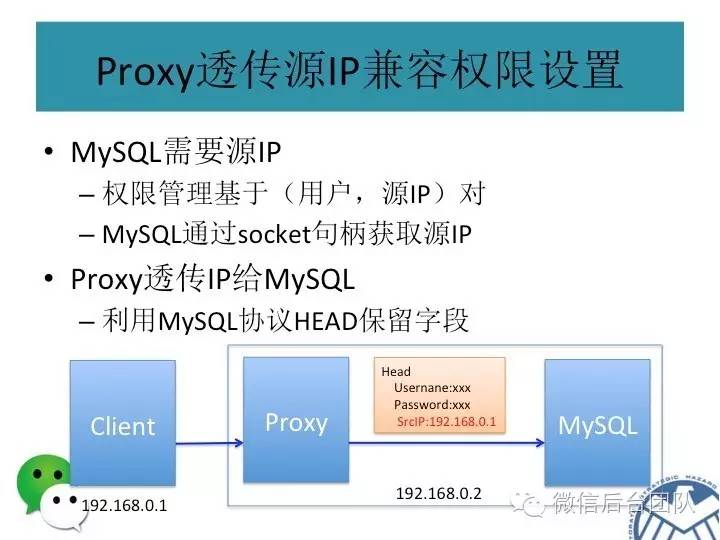
实际上, PhxSqlProxy也是一个进程,对前端,模仿了mysql服务端,对后端,模仿了mysql客户端,将数据库连接请求平等的对应到后端的mysql服务上;
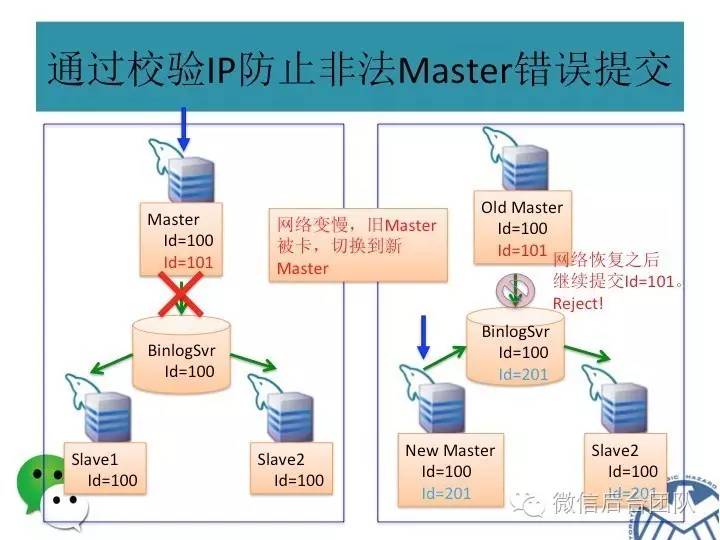
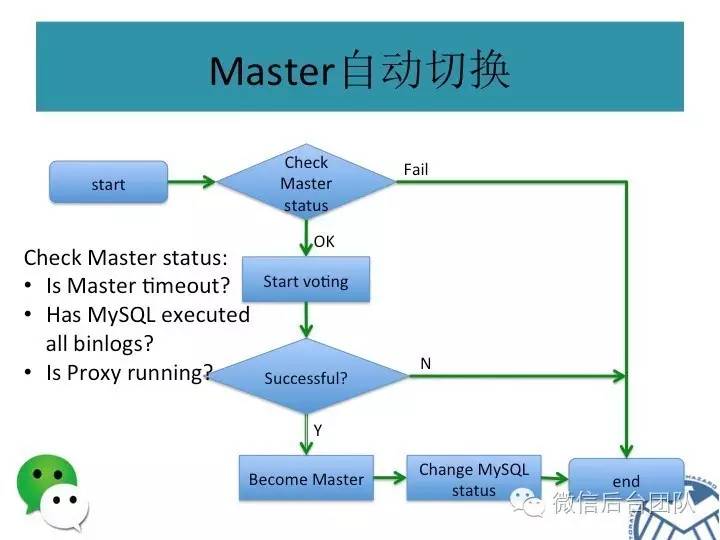
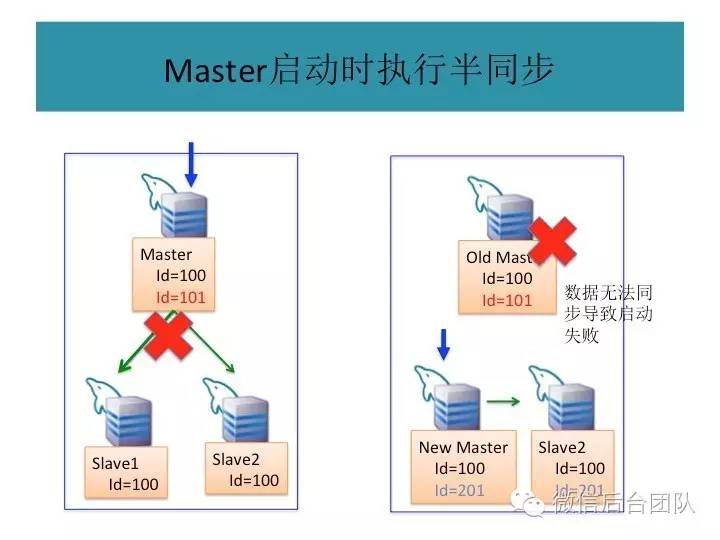
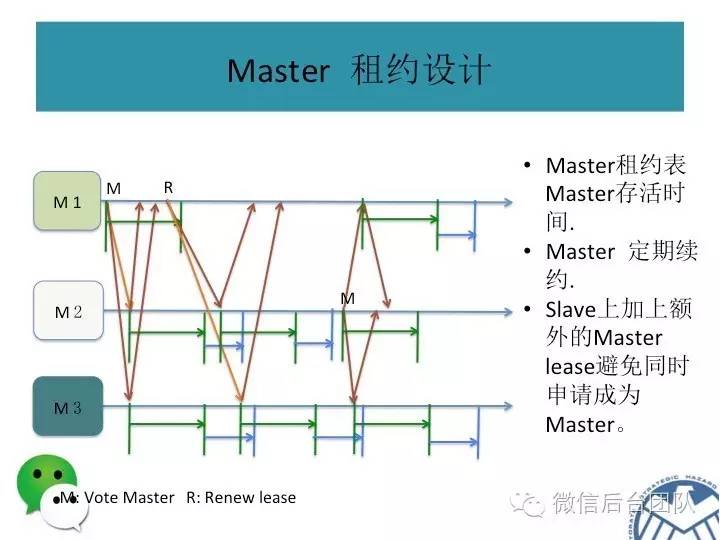
mysql的主库由BinLogSvr来选举,基于paxos算法;
如果有sql请求到来,PhxSqlProxy会向BinLogSvr来查询当前是否为主库,如果是主库,则将请求传给本机的mysql服务;如果是从库,则将请求转给主库;
结束;
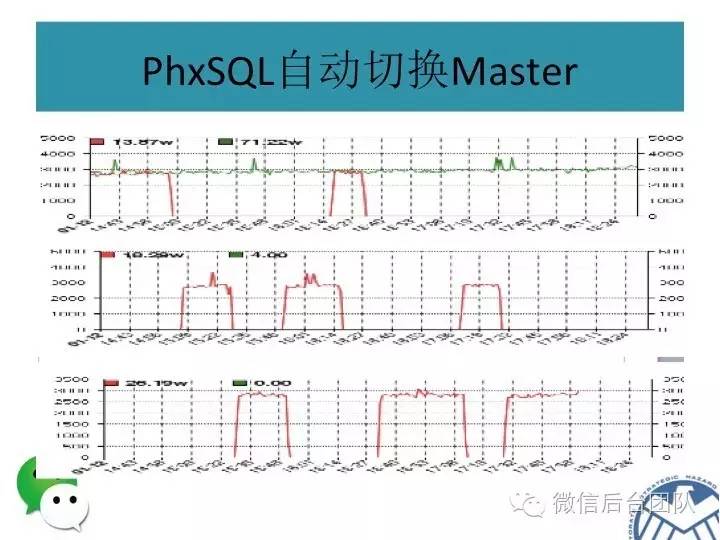
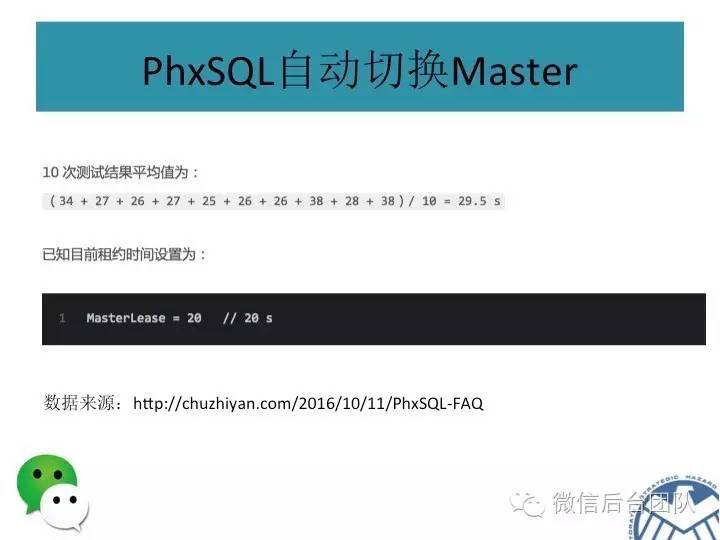
主库挂了或者是租约过期,新的主库选举是由BinlogSvr来完成的;
https://blog.csdn.net/laogouhuli/article/details/92591386
对比部署方案
随着平台升级,单节点数据库提供服务已力不从心。现在需要确定一套集群方案用以部署mysql5.7集群。在这里和大家分享下经历,难免会有些许错误,请各位看官不吝赐教。
需求明确
可以预见数据库运行的环境如下:
内网运行
部署维护便利
考虑迁移性
定期备份
横向扩展
主备,热切换,读写分离,易恢复
ok,需求明确了,下一步寻找方案
对比方案
我们团队在开发前期前期已确定数据库采用mysql5.7,再此基础上搜索了主流的
集群部署方式。
MySQL Replication架构
MySQL Replication是MySQL非常出色的一个功能,该功能将一个MySQL实例中的数据复制到另一个MySQL实例中。整个过程是异步进行的,但由于其高效的性能设计,复制的延时非常小。多数的集群方案都基于此功能进行设计。
MySQL的复制(replication)是一个异步的复制,从一个MySQLinstace(称之为Master)复制到另一个MySQLinstance(称之Slave)。整个复制操作主要由三个进程完成的,其中两个进程在Slave(Sql进程和IO进程),另外一个进程在Master(IO进程)上。
要实施复制,首先必须打开Master端的binarylog(bin-log)功能,否则无法实现。因为整个复制过程实际上就是Slave从Master端获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。复制的基本过程如下:
Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
Master接收到来自Slave的IO进程的请求后,通过负责复制的IO进程根据请求信息读取指定日志指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置;
Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log的某个位置开始往后的日志内容,请发给我”;
Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
结论
功能太单一,不符需求,不考虑。
MMM架构
MySQL-MMM是Master-Master Replication Manager for MySQL(mysql主主复制管理器)的简称,是Google的开源项目(Perl脚本)。
MMM基于MySQL Replication做的扩展架构,主要用来监控mysql主主复制并做失败转移。其原理是将真实数据库节点的IP(RIP)映射为虚拟IP(VIP)集,在这个虚拟的IP集中,有一个专用于write的IP,多个用于read的IP,这个用于Write的VIP映射着
数据库集群中的两台master的真实IP(RIP),以此来实现Failover的切换,其他read的VIP可以用来均衡读(balance)。
优点:
自动的主主Failover切换,一般3s以内切换备机
多个Slave读的负载均衡。
缺点:
无法完全保证数据的一致性(在db1宕机过程中,一旦db2落后于db1,这时发生切换,db2变成了可写状态,数据的一致性就无法保证)
无论何时,只有一个数据库可写;db1宕机后,write VIP会指向db2,当db1恢复后,db1不会自动变成可写主,需要手动move_role 或者db2宕机。
所以read host要包括db1,不然容易造成浪费;
由于是使用虚拟IP浮动技术,类似Keepalived,故RIP(真实IP)要和VIP(虚拟IP)在同一网段;如果是在不同网段也可以,需要用到虚拟路由技术。
monitor单点问题,或许可以用keepalived来解决。
结论
MMM架构在以前非常流行,但现在难免有些落伍,mysql本质上还是已单机模式安装在服务器上,无法方便的横向扩展。不考虑
MHA架构
MHA(Master High Availability)由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作(以2019年的眼光来说太慢了),并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
某种意义上来说MHA架构是MMM架构的升级版,但是又缺少了vip的功能,一般会配合keepalived使用补完vip的功能。
优点
自动监控Master故障转移、故障后节点之间的数据同步
不会有性能损耗,适用于任何存储引擎
具备自动数据补偿能力,在主库异常崩溃时能够最大程度的保证数据的一致性
可实现同城应用级别双活
最大程度上保证数据的一致性
缺点
MHA架构实现读写分离,最佳实践是在应用开发设计时提前规划读写分离事宜,在使用时设置两个连接池,即读连接池与写连接池,也可以选择折中方案即引入SQL Proxy。但无论如何都需要改动代码;
关于读负载均衡可以使用F5、LVS、HAPROXY或者SQL Proxy等工具,只要能实现负载均衡、故障检查及备升级为主后的读写剥离功能即可,建议使用LVS;
MHA Manager Node 主要负责主库在crash时将bin log完整同步到slave库、监控主备库的状态及切换。
结论
最大的问题做读写分离时需要改动代码,与开发耦合太高,不利于当前部署以及后期改造。不考虑。
InnoDB Cluster架构
MySQL InnoDB集群为MySQL提供了完整的高可用性解决方案。 MySQL Shell包含AdminAPI,使您可以轻松配置和管理一组至少三个MySQL服务器实例,以充当InnoDB集群。 每个MySQL服务器实例都运行MySQL Group Replication,它提供了在InnoDB集群内复制数据的机制,具有内置故障转移功能。Admin API无需在InnoDB集群中直接使用组复制。 MySQL Shell可以根据您部署的集群自动配置自身,将客户端应用程序透明地连接到服务器实例。如果服务器实例意外故障,群集将自动重新配置。在默认的单主模式下,InnoDB集群具有单个读写服务器实例 - 主要实例。多个辅助服务器实例是主要副本的副本。如果主服务器出现故障,则辅助服务器将自动升级为主服务器。MySQL路由器检测到此情况并将客户端应用程序转发到新主服务器。高级用户还可以将群集配置为多主结构。
一般采用MySQL Router、Cluster和MySQL Shell构成的Mysql InnoDB Cluster高可用方案进行搭建
结论:
InnoDB Cluster支持自动Failover、强一致性、读写分离、读库高可用、读请求负载均衡,横向扩展的特性,是比较完备的一套方案。但是部署起来复杂,想要解决router单点问题好需要新增组件,如没有其他更好的方案暂考虑该方案。
Mycat架构
基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得MYCAT一开始就拥有一个很好的起点。一个彻底开源的,面向企业应用开发的大数据库集群。
功能介绍
支持事务、ACID、可以替代MySQL的加强版数据库
一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
一个新颖的数据库中间件产品
MYCAT监控
1.支持对Mycat、Mysql性能监控
2.支持对Mycat的JVM内存提供监控服务
3.支持对线程的监控
4.支持对操作系统的CPU、内存、磁盘、网络的监控
优点
Mycat作为主数据库中间件,是与代码弱关联的,所以代码是不用修改的,使用Mycat后,连接数据库是不变的,默认端口是8066。连接方式和普通数据库一样,如:jdbc:mysql://192.168.0.2:8066/
自带监控,提供较全面的监控服务
可实现数据库的读写分离,在后端的主从复制数据库集群中,通过MYCAT配置,将前台的写操作路由到主数据库中,将读操作路由到从数据库上。
MYCAT可以实现读写分离下的读操作负载均衡,将大量的读操作均衡到不同的从库上,主要出现在一主多从情形下。
MYCAT可实现数据库的高可用,在数据库主节点可用的情况下,配置一台可写从节点,这两个节点都配置在MYCAT中,当主节点宕机时,MyCAT会自动将写操作路由到备用节点上,但并不支持在切换之后的继续主从同步。
当读写分离已经不能满足持续增加的访问量时,MYCAT可实现数据库的垂直拆分,将所有的数据库表按照模块划分,不同类型的表拆分到不同的数据库服务器。
随着业务量的增长,垂直拆分之后如果又出现了数据库性能问题,则需要进行水平切分,这就是俗称的分库分表。将数据量很大的表数据切分到不同的服务器库中,表结构是一样的,而使用MYCAT实现水平切分,对前端应用是完全透明的,不用调整前台逻辑。
缺点
TPS性能低下
最近版本维护越来越少了
总结
Mycat也并不是配置以后,就能完全解决分表分库和读写分离问题。Mycat配合数据库本身的复制功能,可以解决读写分离的问题,但是针对分表分库的问题,不是完美的解决。或者说,至今为止,业界没有完美的解决方案。
分表分库写入能完美解决,但是,不能完美解决主要是联表查询的问题,Mycat支持两个表联表的查询,多余两个表的查询不支持。 其实,很多数据库中间件关于分表分库后查询的问题,都是需要自己实现的,而且节本都不支持联表查询,Mycat已经算做地非常先进了。分表分库的后联表查询问题,需要通过合理数据库设计来避免。这是一套比较好的数据库集群方案,值得考虑。
PhxSQL
优点
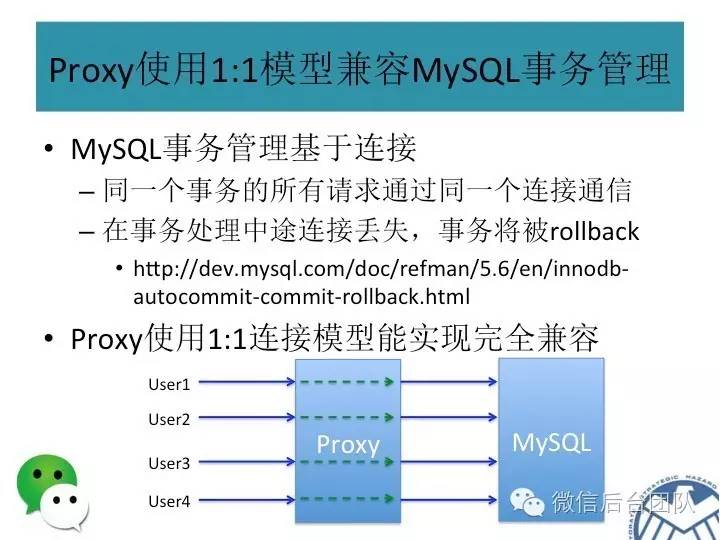
高性能:由于Proxy接管了MySQL Client的请求,为了使整个集群的读写性能接近单机MySQL,Proxy使用协程模型提高自身的处理能力。
Proxy的协程模型使用开源的Libco库。Libco库是微信团队开源的一个高性能协程库,具有以下特点:
用同步方式写代码,实现异步代码的性能。
支持千万级的并发连接。
项目地址https://github.com/tencent-wechat/libco
完全兼容MySQL:为了已有的应用程序能够不做任何修改就能迁移到PhxSQL,Proxy需兼容MySQL的所有功能。
缺点
MySQL Fabric.
Oracle在2014年5月推出了一套为各方寄予厚望的MySQL产品 – MySQL Fabric,从字面上不太能看出它是啥,但是从名称上还是有迹可循的。fabric是“织物”的意思,这意味着它是用来“织”起一片MySQL数据库。MySQL Fabric是一套数据库服务器场(Database Server Farm)的架构管理系统。
MySQL Fabric是什么?
MySQL Fabric能“组织”多个MySQL数据库,是应用系统将大于几TB的表分散到多个数据库,即数据分片(Data Shard)。在同一个分片内又可以含有多个数据库,并且由Fabric自动挑选一个适合的作为主数据库,其他的数据库配置成从数据库,来做主从复制。在主数据库挂掉时,从各个从数据库中挑选一个提升为主数据库。之后,其他的从数据库转向新的主数据库复制新的数据。注意:这里说的“自动”是指由MySQL Fabric在后台完成,而不需要用户手动更改配置。最重要的是,MySQL Fabric是GPL的开源软件,也就是在符合GPL的规范下,你可以自由的使用和修改这个软件。
mysql备份
关于数据的备份,其实是件比较头疼的事,服务器容量有限,不可能存放在磁盘上,幸好项目环境是运行在阿里云的内网环境的云服务器上,可以连接阿里云oss。遂决定采用以下方案:
上传binlog日志至oss
结合crontab设定定时任务,周期的上传文件至oss
上传数据库备份至oss
创建备份用户,在上传日志文件时,同时触发mysqldump 脚本生成sql文件上传至oss
总结
综合考虑,在满足横向扩展,主备,热切换,读写分离,易恢复等基础需求上,公司人手有限又是内网部署,需要一套易部署维护的,要与开发代码无关的部署反感,个人比较倾向与PhxSQL.
更6月17日更新
需求补充,项目需要分场景部署两套集群:
该场景下会频繁进行插入操作,偶尔的单表读操作,不会有更新操作,会有大量数据存储,需要保证数据强一致性。
该场景下会频繁进行单表读操作,偶尔的单表插入操作,不会有更新操作
https://blog.csdn.net/weixin_29115985/article/details/79580505
PhxSQL学习--腾讯开源的分布式数据库服务
前言
以前在开发电商项目时,使用的是主流的方法:通过对MySQL进行主从复制,及利用Amoeba实现数据库读写分离,来搭建一个较为稳定且能承受并发量大的服务数据库。然而在使用过程中,慢慢发现无论是一主两从还是一主多从也好,这两种方式的同步都会有时间差,在非常大的并发下,同步的时间差就会暴露出来,导致可能查询的数据读到脏数据。所以分布式数据库也许才是最好的解决方案。
在寻找不同数据库高可用方案时,找到keepalived,MHA以及引入zookeeper的等等方案,这些方法在强一致性、数据库选择的灵活性、整体系统的复杂性和维护性上都有一定的不足。对于企业来说,数据的高可用性和强一致性是最为看重的,一旦因为一次意外丢失了数据,很有可能会让企业陷入不小的风险当中。
通过寻找和了解,很快找到两个开源的且比较适合的可用方案,分别是阿里的AliSQL和腾讯的PhxSQL。两个开源的且兼容MySQL的数据库经对比,不难发现这两个研究的方向还是有点不一样的:
AliSQL是MySQL的一个分支,通过对MySQL进行优化(侵入到MySQL内部,内核级开发),对数据库作了功能及性能上的优化。
PhxSQL是使用分布式协议paxos写了一个binlog同步的插件,它解决了数据一致性的问题,保证多节点的MySQL使用该插件同步binlog可以达到binlog的强一致性。保证数据库的高可用和强一致的同时,对MySQL的侵入性较小。
显而易见,对于电商项目,阿里的AliSQL是一个不错的选择;对于企业项目,腾讯的PhxSQL实用性会更高一点。
PhxSQL简介
PhxSQL是由微信后台团队自主研发的一款数据强一致、服务高可用的分布式数据库服务。PhxSQL提供Zookeeper级别的强一致和高可用,完全兼容MySQL。源码地址
PhxSQL具有服务高可用、数据强一致、高性能、运维简单、和MySQL完全兼容的特点。
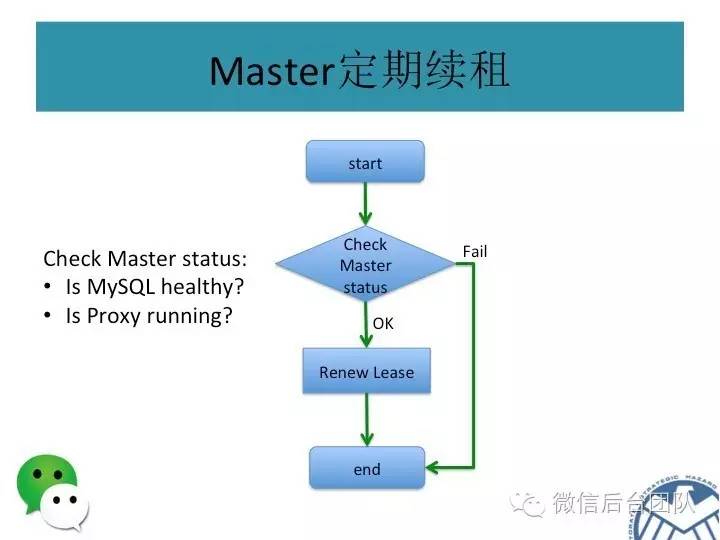
服务高可用:PhxSQL集群内只要多数派节点存活就能正常提供服务;出于性能的考虑,集群会选举出一个Master节点负责写入操作;当Master失效,会自动重新选举新的Master。
数据强一致:PhxSQL采用多节点冗余部署,在多个节点之间采用paxos协议同步流水,保证了集群内各节点数据的强一致。
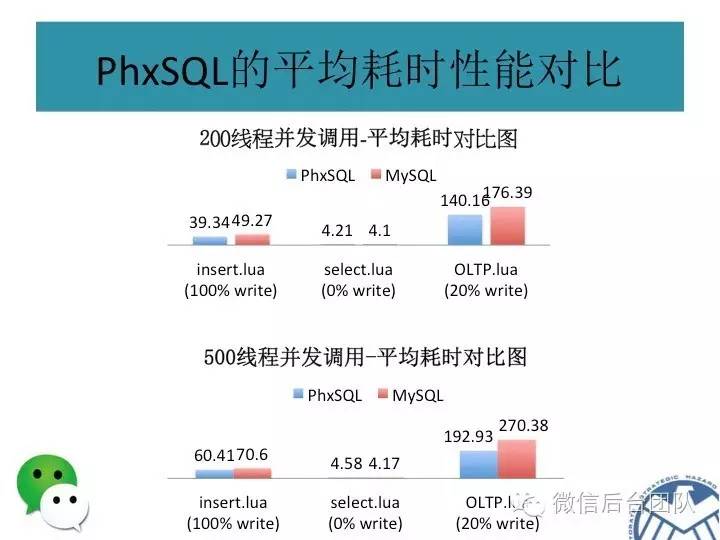
高性能:PhxSQL比MySQL SemiSync的写性能更好,得益于Paxos协议比SemiSync协议更加高效;
运维简单:PhxSQL集群内机器出现短时间故障,能自动恢复数据,无需复杂的运维操作;PhxSQL更提供一键更换(新增/删除)集群内的机器,简化运维的工作。
MySQL完全兼容:PhxSQL是基于Percona的研发,完全兼容MySQL的操作命令。 可通过MySQL提供的mysqlclient/perconaserverclient直接操作PhxSQL。
项目中包含PhxSQL源代码,源代码编译时所需要的一些第三方库,及可直接在Linux环境下运行的二进制包。其中代码使用到了微信团队自研的另外三个开源项目(phxpaxos,phxrpc,colib)。若需编译源代码,需额外下载,也可以在clone时通过--recurse-submodule获得代码。
phxpaxos项目地址: http://github.com/Tencent/phxpaxos
phxrpc项目地址: http://github.com/Tencent/phxrpc
colib项目地址: http://github.com/Tencent/libco
PhxSQL编译
安装部署PhxSQL之前,需要对开源项目进行编译,打包。
1. (注意)在按照官方文档一步一步编译之前,首先安装依赖包,如果不能联网的话,请自行下载好相关的rpm包:
yum -y install readline*
yum -y install zlib*
yum -y localinstall libstdc++-static
yum -y localinstall glibc-static
yum -y localinstall nscd
2. 按照以下链接的编译步骤即可完成编译:
官方的中文详细编译手册:https://github.com/Tencent/phxsql/wiki/中文详细编译手册
3. 编译完成后,生成安装文件:
(1)在PhxSQL目录下执行sh autoinstall.sh && make && make install
(2)若想打包二进制运行包(集群运行时所需要的所有文件和配置)make package
(3)install完成后,二进制会生成到PhxSQL目录下的sbin目录,运行所需要的相关文件和配置会安装到PhxSQL目录下的install_package目录。打包二进制运行包会把install_package进行tar格式的打包,并生成phxsql.tar.gz。若想更改install的安装目录,可在sh autoinstall.sh 后加入-prefix=路径
PhxSQL部署
1. PhxSQL需要在2台或以上的机器集群上运行(建议集群内机器数目n>=3 且 n为奇数)。
本人搭建时选用了3台机器:
IP1
IP2
IP3
2. my.cnf的修改:MySQL的配置根据你的业务需求进行修改(安装前请修改tools/etc_template/my.cnf,安装后请修改etc/my.cnf)。
本人在安装前,在my.cnf中的[mysqld]后添加:
lower_case_table_names = 1
此处修改原因是:在Linux下,mysql安装完后是默认:区分表名的大小写,不区分列名的大小写!而MySQL在Windows下都不区分大小写。因为尝试过在安装之后再修改是不成功的,为了防止数据库出错,所以在安装前修改。
3. 按照以下链接的部署步骤即可完成部署:
官方的中文部署手册:https://github.com/Tencent/phxsql/wiki/中文部署手册
此处顺便整理下本人的部署过程,有兴趣可以对比下:
(1)第一次安装时
groupadd mysql
useradd -g mysql mysql
passwd mysql
(2)编译完成的二进制包改名为 phxsql.tar.gz 并放在 /home 目录中(三台机器都要执行)
tar xvf phxsql.tar.gz
mkdir /home/phxsqldata
注意:不要放在 /root 目录下,亲测因为权限问题,安装后会出各种奇怪的错误。
查看 /home 目录,即可找到以下的部署路径:
安装路径
数据路径
编译后的安装包
(3)开始安装部署(每台机器都要执行,只需要修改最后一句,对应为当前机器的IP即可)
cd /home/phxsql/tools
python2.7 install.py -i "192.168.8.236" -p 54321 -g 6000 -y 11111 -P 17000 -a 8001 -f /home/phxsqldata/
(4)安装完成后查看服务和端口是否可用
ps -ef | grep phxsqlproxy
ps -ef | grep mysql
ps -ef | grep phxbinlogsvr
netstat -ntlp
出现下图的红色方框中的服务和端口,即代表安装成功:
如果存在没有正常启动的二进制,执行 python2.7 restart.py -p 二进制名,启动相应二进制。
(5)此处是为了操作方便,配置下环境变量,就可以在任何地方使用phxbinlogsvr_tools_phxrpc、mysql等命令
vim /etc/profile
在此文件中增加以下两句话,保存即可:
export PATH=/home/phxsql/sbin:$PATH
export PATH=/home/phxsql/percona.src/bin/:$PATH
重新加载 profile 文件:
source /etc/profile
(6)建立集群(官方说在任意一台机器上执行即可,但经过测试,貌似在设置的主机上跑才不容易出错)
phxbinlogsvr_tools_phxrpc -f InitBinlogSvrMaster -h"192.168.8.236,192.168.8.237,192.168.8.238" -p 17000
(7)出现以上红色框框的部分就代表集群已经搭建成功了,可以用命令查看集群内的成员及主机信息(上图可以看到)
phxbinlogsvr_tools_phxrpc -f GetMemberList -h"192.168.8.236" -p 17000
phxbinlogsvr_tools_phxrpc -f GetMasterInfoFromGlobal -h"192.168.8.236" -p 17000
(8)这里特别说下,集群安装部署失败需要重新安装部署,此时最好在 kill 掉端口的同时也要 kill 掉服务,及相关目录中存放的数据,防止后面重新部署时出现相同的服务导致集群有问题。
killall -9 phxbinlogsvr_phxrpc phxsqlproxy_phxrpc mysqld
rm -rf /home/phxsqldata
rm -rf /home/phxsql
然后回到第(2),重新开始即可。
(9)登陆PhxSQL并测试
通过Phxsqlproxy登陆PhxSQL的Master进行读写:
mysql -uroot -h "192.168.8.236" -P 54321
通过Phxsqlproxy登陆PhxSQL的slave读取数据:
mysql -uroot -h "192.168.8.237" -P 54322
mysql -uroot -h "192.168.8.238" -P 54322
(10)重启机器或者修复好集群机器后,需要要重新启动Phxsql各组件
cd /home/phxsql/tools
python2.7 restart.py -p mysql
python2.7 restart.py -p phxbinlogsvr
python2.7 restart.py -p phxsqlproxy
PhxSQL官方文档
中文详细编译手册
中文部署手册
PhxSQL 成员管理
从现有MySQL数据库迁移
PhxSQL官方文章
MySQL半同步复制的数据一致性探讨
PhxSQL架构介绍
PhxSQL强一致同步基础PhxPaxos库原理介绍
谈谈PhxSQL的设计和实现哲学(上)
谈谈PhxSQL的设计和实现哲学(下)